November 2025

Figure : Comparative performance of YBA RAG (MAGAR) against leading In Context systems
Evaluation of YBA MAGAR
Matching frontier systems on MuSiQue — in zero-shot
November 2025
Summary
YBA MAGAR reaches 59.08% answer correctness on the MuSiQue multi-hop QA benchmark — on par with Microsoft's fine-tuned PIKE-RAG (59.60%) — while achieving the highest Exact Match (53.2%) and F1 (69.5%) scores among all systems compared. MAGAR does this in a strictly zero-shot setting, with no fine-tuning on the benchmark, outperforming Salesforce, Google, Huawei, and Peking University's HopRAG.
Abstract
We introduce MAGAR (Multi-Agent Graph-Augmented RAG), a retrieval-augmented generation framework that combines graph-based retrieval with multi-agent orchestration to support robust, multi-step, in-context reasoning over enterprise knowledge. To assess MAGAR's generality for multi-hop reasoning, we benchmarked it on MuSiQue, a public multi-document, multi-hop question-answering dataset. This report presents the evaluation results, explains the protocol, and provides reproducibility notes. All numeric results are taken from our evaluation materials and have not been altered.
About YBA.ai
YBA.ai builds in-context agents that automate knowledge work. MAGAR combines graph-based retrieval with multi-agent orchestration to deliver multi-step reasoning and evidence-backed answers — with provenance — from a company's data and knowledge bases. Multi-hop questions, which require linking facts across several documents and performing intermediate reasoning, remain a major challenge for standard retrieve-then-generate pipelines. MAGAR augments vector retrieval with a graph representation of knowledge and coordinates multiple specialized agents to produce grounded answers.
Why MuSiQue?
MuSiQue rigorously probes complex reasoning. Each question requires the system to:
Reason across multiple documents — the evidence is scattered and must be found in different places.
Integrate evidence — perform intermediate reasoning steps and link semantically diverse facts into a single, consistent answer.
This maps directly onto MAGAR's core strengths: modeling the relationships between information chunks and preserving coherent reasoning sequences through graph-based retrieval. Dataset: https://arxiv.org/abs/2108.00573
Evaluation methodology
We evaluate with standard RAG metrics:
Answer Correctness — computed with the RAGAS framework (LLM-as-judge, scored 0–1): how factually accurate and complete the answer is versus the ground truth.
Exact Match (EM) — whether the ground-truth answer appears exactly in the generated text.
F1 — the balance of precision and recall at the token level (precision = matched / generated tokens; recall = matched / ground-truth tokens).
Model and setting. MAGAR runs on GPT-4o in a strictly zero-shot setting: no fine-tuning on MuSiQue and no in-context examples. This is in deliberate contrast to Microsoft's PIKE-RAG, which is fine-tuned on the MuSiQue training split.
We evaluate under two scenarios:
Full answerable dev set (1,127 questions) — comprehensive coverage across question types and difficulty levels.
Random answerable subset (500 questions) — reported for direct comparability with Microsoft, Salesforce, and Huawei, which also evaluated on 500 questions.
On the full 1,127-question set, MAGAR scores 46.50% Answer Correctness, 36.29% EM, 53.30% F1. On the 500-question subset, it scores 59.08% Answer Correctness, 53.20% EM, 69.50% F1. The figures reported below are the 500-question results, for like-for-like comparison; the full-set figures are provided for transparency.
Benchmarking against industry and academic work
Each system below was evaluated by its own authors, under its own protocol. We compile their published results and annotate the methodological differences rather than re-running them, to avoid introducing our own bias.
Microsoft — PIKE-RAG (Jan 2025): fine-tuned LLM, including the MuSiQue "train" split; 500 random dev questions. Answer Correctness 59.60%, EM 46.40%, F1 56.60%.
Google — Speculative RAG (Jul 2024): unspecified number of questions; reported Answer Correctness only — 31.57%.
Salesforce — GPT-4o RAG + HyDE (Dec 2024): 500 random dev questions; reported Answer Correctness only — 52.20%.
Peking University — HopRAG (Feb 2025): 1,000 dev questions, GPT-4o reader; EM 42.2%, F1 54.9%.
Huawei — GeAR (Dec 2024): 500 random questions; EM 19.0%, F1 35.6%.
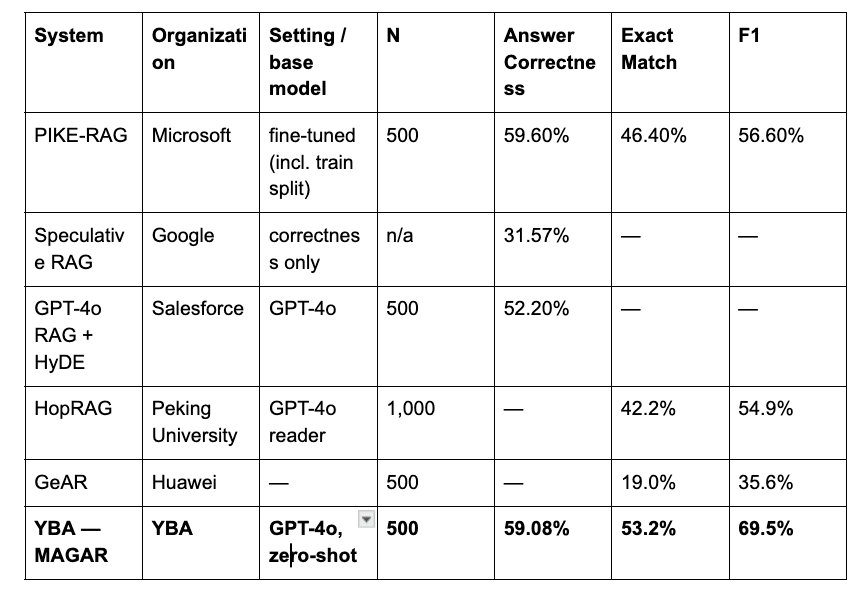
Google's Speculative RAG and Salesforce's RAG + HyDE report Answer Correctness only; HopRAG and GeAR report EM and F1 only. "—" denotes a metric not published by that author.
Performance analysis
MAGAR delivers one of the strongest overall results on MuSiQue.
MAGAR's 59.08% answer correctness essentially matches Microsoft's fine-tuned PIKE-RAG (59.60%) — a notable result given that MAGAR uses no fine-tuning on the benchmark.
Like-for-like architectural gain. Against Salesforce's GPT-4o RAG + HyDE — which shares MAGAR's GPT-4o base model — MAGAR improves answer correctness by nearly 7 points (59.08% vs 52.20%). With the base model held constant, this isolates the contribution of the MAGAR architecture itself.
Best Exact Match and F1. MAGAR achieves the highest EM (53.2%) and F1 (69.5%) of all systems compared, ahead of Microsoft (46.4 / 56.6), HopRAG (42.2 / 54.9), and GeAR (19.0 / 35.6). These two metrics measure the consistency between retrieved context and generated answers — the property that matters most for autonomous, multi-step execution.
Reproducibility note
All MAGAR results are derived from the MuSiQue development set using standard RAG evaluation metrics. Cross-system comparisons combine each author's own published protocol; sample sizes, base models, and reported metrics differ, as annotated in the table above. The MAGAR evaluation protocol is available on request.